| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Memory Model
Die Kosten der Synchronisation
Java Magazin, September 2008
|
Dies ist das
Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective
Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser
Serie sind ebenfalls verfügbar (
click
here
).
|
In den bisherigen beiden Beitrag unserer Reihe über Aspekte des Java-Memory-Modells (JMM) haben wir uns die Grundzüge des Modells und seine Sichtbarkeitsregeln angesehen (siehe / JMM2 /). Weiter haben wir ein Beispiel für einen typischen Fehler betrachtet, der sich aus der Mißachtung des JMM ergeben kann (siehe / JMM1 /). In diesem Beitrag wollen wir nun genauer darauf eingehen, warum man die Regeln des JMM überhaupt kennen sollte. Vielfach wird ausschließlich mit Synchronisation gearbeitet, so dass volatile-, final- und atomare Variablen kaum eine Rolle spielen. Wozu soll man sich also mit den JMM-Regeln dafür befassen? In diesem Beitrag wollen wir uns ansehen, welche Schwachpunkte Synchronisation hat und warum sie in Zukunft in zunehmendem Maße durch andere Techniken, die volatile-, final- und atomare Variablen benötigen, ersetzt werden wird.
Synchronisation von konkurrienden Zugriffen auf gemeinsam verwendete veränderliche Daten mit Hilfe von Locks ist in vielen Fällen unerlässlich, um die Konsistenz der Daten sicher zu stellen. Leider sind mit der Synchronisation Kosten verbunden. Zum einen sind es Performance-Kosten, die einfach dadurch entstehen, dass Synchronisation mit Arbeit verbunden ist, die das Laufzeitsystem erbringen muss. Zum anderen sind es Kosten, die durch einen Mangel an Skalierbarkeit entstehen.
Performance-Einbußen durch Synchronisation
Das Anfordern und Freigeben eines Locks löst eine Reihe von Aktionen im Laufzeitsystem aus, die CPU-Zeit und damit Ablauf-Performance kosten.So muss beim Anfordern eines Locks die zu dem Lock gehörende Warteschlange gefunden, abgefragt und ggf. modifiziert werden. In der Warteschlange stehen all die Threads, die darauf warten, das Lock nach seiner Freigabe zu bekommen. Die Verwaltung dieser Warteschlange kostet CPU-Zeit und Ressourcen.
Die tatsächliche Zuteilung eines Locks an einen Thread löst nicht nur den Update von Verwaltungsinformation in der virtuellen Maschine aus (das Lock ist jetzt besetzt und diese Information muss vermerkt werden), sondern auch Memory Barriers, die dafür sorgen, dass der nun aktivierte Thread seinen Cache auffrischt. Eine solche Memory Barrier ist eine Anweisung, die die virtuelle Maschine an die Hardware der Maschine erteilt, damit Prozessoren ihre Caches mit dem Hauptspeicher abgleichen. Dieser Abgleich ist erforderlich, weil er von den Sichtbarkeitsregeln des JMM verlangt wird, wie wir im letzten Beitrag erläutert haben (siehe / JMM2 /). Eine solche Memory Barrier reduziert die Effizienz der Prozessoren, weil sie in den Caching-Algorithmus der Hardware eingreift. Das heißt, die mit der Synchronisation verbundenen Speichereffekte kosten Performance.
Die Freigabe eines Locks löst erneut Zugriffe auf die zu dem Lock gehörende Warteschlange aus, denn einer der wartenden Threads muss aufgeweckt werden. Die Freigabe des Locks löst außerdem erneut eine Memory Barrier aus, damit der freigebende Thread seine Cache-Inhalte den anderen Threads sichtbar macht.
All dies sind Aufwände, die allein durch die Synchronisation entstehen. In einer Single-CPU-Umgebung sind dies zusätzliche Laufzeitkosten, die nicht durch Laufzeitgewinn an anderer Stelle kompensiert werden. In einer Multiprozessor-Umgebung wird der Overhead in der Regel durch die erhöhte Ausnutzung der Prozessorleistung ausgeglichen oder sogar überkompensiert.
Wie hoch die Kosten der Synchronisation sind, läßt sich allgemein nicht sagen, sondern kann nur durch eine entsprechende Messung in der jeweils relevanten Umgebung verlässlich bestimmt werden, weil der Overhead von der Implementierung der virtuellen Maschine und deren Zusammenspiel mit dem Betriebsystem und der Hardware abhängt. Dass die Implementierungen unterschiedlich sind, kann man bereits daran sehen, dass in der virtuellen Maschine von Sun die alten impliziten Locks dahingehend optimiert sind, dass sie relativ preiswert sind, wenn es keine Konkurrenz beim Anfordern des Locks gibt, wohingegen die neuen expliziten Locks dahingehend optimiert sind, dass sie effizient sind, gerade wenn es sehr viel Konkurrenz gibt.
Die Laufzeiteinbußen durch Memory Barriers, die Verwaltung der Warteschlange, etc. machen aber nur einen Teil der Kosten der Synchronisation aus. Hinzu kommt noch die Einbuße an Skalierbarkeit.
Skalierbarkeitseinbußen durch Synchronisation
Synchronisation mit Hilfe von Locks führt dazu, dass gewisse Teile des Programms immer nur von einem Thread zu einer Zeit ausgeführt werden können. Das führt unter Umständen dazu, dass viele Threads warten und nur wenige Threads aktiv sind. Insgesamt ergibt sich daraus eine schlechte Ausnutzung der Prozessorleistung. Das ist in Multicore- und Multi- Prozessor-Umgebungen nachteilig, weil die Leistung der vielen Kerne bzw. Prozessoren nicht angemessen genutzt wird. Wenn im ungünstigsten Falle nur ein einziger Thread aktiv ist und alle anderen warten, dann wird auch nur ein einziger Kern bzw. Prozessor ausgelastet und alle anderen bleiben ungenutzt. Das heißt, Programme mit viel Synchronisation skalieren schlecht in dem Sinne, dass sie zusätzliche Ressourcen in Form von zusätzlichen parallelen CPUs nur unzureichend ausnutzen.Üblicherweise wird von einer Anwendung aber erwartet, dass sie auf einer Architektur mit höherer Prozessorleistung schneller abläuft. Dies wird auch erwartet, wenn die höhere Prozessorleistung nicht durch eine erhöhte Prozessorgeschwindigkeit, sondern durch durch eine erhöhte Anzahl von Prozessoren bzw. Prozessorkernen erbracht wird. Dabei ist die naive Erwartung an ein Programm meist, dass es beim Ablauf auf einem System mit zwei CPUs doppelt so schnell läuft wie auf einem System mit einer einzelnen CPU vom gleichen Typ. Diese einfache Rechnung ist aber falsch.
Amdahl's Law
Der theoretisch erzielbare Performance-Gewinn durch zusätzliche Prozessoren wird nach dem Gesetz von Amdahl (siehe / AMDL /) bestimmt. Dazu ermittelt man den Prozentsatz des Programms, der parallel abläuft, und den Teil des Programms, der nicht parallelisierbar ist. Zu dem nicht parallellisierbaren Teil des Programms gehören alle synchronisierten Teile des Programms.Wenn F der Bruchteil ist, der nicht parallel ablaufen kann, und N die Zahl der Prozessoren, dann ist der maximal erreichbare Performance-Zugewinn begrenzt durch:
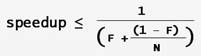
Bei unendlich vielen Prozessoren, konvergiert der maximale Performance-Zugewinn gegen 1/F. Wenn also 50% eines Programms parallel ablaufen und 50% sequentiell, dann wird das Programm maximal (bei unendlich vielen Prozessoren) doppelt so schnell. Beim Umstieg von einem auf zwei Prozessoren wird es lediglich um maximal 25% schneller. Das heißt, die naive Rechnung "doppelt so viele CPUs = doppelt so schnell" ist meist höchst unzutreffend.
Der Zugewinn wächst mit der Zahl der verfügbaren Prozessoren, aber auch mit dem Prozentsatz der Parallelverarbeitung in der Anwendung. Synchronisation jedoch reduziert den Anteil, der parallel ablaufen kann. Hier ist eine ernüchternde Grafik, die den Performance-Gewinn je zusätzlichem Prozessor zeigt abhängig vom nicht-parallelisierbaren Anteil des Programms:
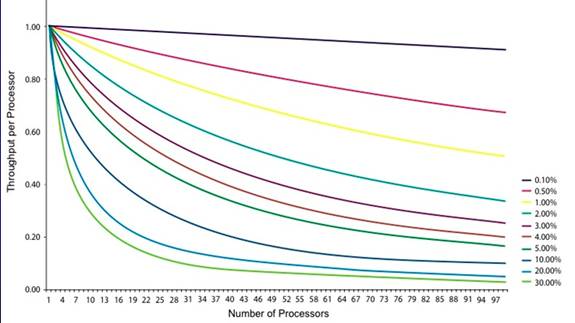
Wenn nur 0,1% nicht-parallel ablaufen, dann ist der Zugewinn mit jedem
zusätzlichen Prozessor ungefähr gleich. Das ist erfreulich,
aber welche Anwendung läuft zu 99,9% parallel ab? Kaum eine. Wenn
aber 30% nicht-parallel ablaufen, dann bringen der 5. oder 6. Prozessor
nur noch 30-40% an Performance-Gewinn. Den 10. oder 12. Prozessor
kann man sich eigentlich schon schenken, weil er kaum noch etwas bringt
für die Performance.
Vollständig parallel?
Nun ist es in der Praxis schwierig, den Prozentsatz an Parallelverarbeitung in einer Anwendung präzise zu bestimmen. Bestenfalls kann man schätzen. Auch dabei leitet die Intuition gelegentlich in die Irre. Selbst Programmteile, die hochgradig parallel aussehen, haben sequentielle Anteile, was oftmals übersehen wird. Sehen wir uns dazu ein Beispiel an: eine Consumer-Producer-Situation, in der Produzenten-Threads Daten in eine LinkedBlockingQueue stecken, die von Konsumenten-Threads aus der Queue geholt und verarbeitet werden.
public boolean offer(E o) {
if (o == null) throw
new NullPointerException();
final AtomicInteger
count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
final ReentrantLock
putLock = this.putLock;
putLock.lock();
try {
if (count.get() < capacity) {
insert(o);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
Man kann sehen, dass es in dieser Methode einen Anteil gibt, der nicht parallel abläuft, sondern der durch ein Lock sequentialisiert ist. Das heißt, um die Konsistenz der von den Threads gemeinsam verwendeten Queue zu sichern, ist ein gewisser Anteil an Sequentialisierung der Zugriffe unerlässlich.
Die Sequentialisierung in dieser Methode ist dabei keineswegs überflüssig oder ungeschickt implementiert. Im Gegenteil, die Implementierung der LinkedBlockingQueue ist hochgradig perfektioniert und nach allen Regeln der Kunst optimiert. Beispielsweise wird Lock-Splitting eingesetzt: statt eines einzigen Locks für die gesamte Datenstruktur gibt es ein putLock und ein takeLock, damit sich Produzenten und Konsumenten nicht gegenseitig behindern. Außerdem werden die Zugriffe auf das Feld count, das die jeweils aktuelle Zahl der Objekte in der Queue angibt, nicht mit Synchronisation gemacht, sondern lock-free mit Hilfe eines AtomicInteger. Zusätzlich werden konkurrierende Zugriffe auf Felder der Datenstruktur von vornherein vermieden, indem lokale Kopien auf dem Stack angelegt und verwendet werden. Aber selbst mit einer so hochoptimierten Implementierung, die sich bemüht, Synchronisation nach Möglichkeit zu vermeiden, bleibt ein kleiner Anteil an Synchronisation unvermeidlich. Die take-Methode sieht so ähnlich aus; auch dort gibt es einen sequentiellen Anteil. Man gelangt also zu der Erkenntnis, dass selbst hochgradig parallele Verarbeitungen geringe sequentielle Anteile haben, die die Skalierbarkeit der Anwendung reduzieren.
Wenn man dann noch überlegt, dass wir in der Regel Frameworks und andere Third-Party-Komponenten (wie hier die LinkedBlockingQueue aus dem JDK) einsetzen, die nicht-parallele Anteilen mitbringen, dann wird langsam klar, dass ein Anteil von 99,9% Parallelverarbeitung in einer Anwendung zwar theoretisch denkbar ist, in der Praxis aber wohl kaum vorkommen dürfte.
Sequentialisierung bekämpfen
| Rücken wir die Aussagen des Gesetzes von Amdahl einmal in die rechte Perspektive. Alles was wir oben zu Skalierbarkeit bei mehreren Prozessoren gesagt haben, gilt uneingeschränkt auch für die Skalierbarkeit bei mehreren Kernen in einem Prozessor. Multicore-Prozessoren sind heutzutage die Norm. Seit das Gesetz von Moore nicht mehr gilt, dem gemäß sich die Prozessorgeschwindigkeit alle 2 Jahre verdoppelt, wird Prozessorleistung nicht mehr durch höhere Leistung eines einzelnen Prozessors erzielt, sondern es werden Prozessoren mit immer mehr Kernen gebaut. Letztes Jahr waren Dual-Core-Prozessoren Stand der Technik. Dieses Jahr sind es Quad-Core-Prozessoren und für die nächste Zukunft sind Prozessoren mit 6-12 Kernen angekündigt. De facto müssen Anwendungen heute so gebaut sein, dass sie die vielen Prozessorkerne auch nutzen. Der Trend geht aufgrund der Hardware-Gegebenheiten dahin, dass Software so geschrieben sein muss, dass sie auch zukünftige Mehrkern-Architekturen ausnutzen kann und mit der Zahl der Prozessorkerne skaliert. Das bedeutet aber, dass Synchronisation reduziert werden muss, weil sie diesem Ziel grundsätzlich im Wege steht. |
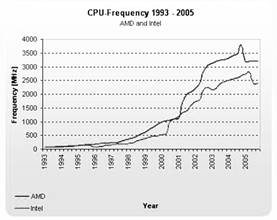
Quelle: Tom's Hardware - Testbericht: "Benchmark-Marathon: 82 CPUs von AMD und Intel" vom 3. November 2005 |
Was kann man also tun, um die sequentiellen Anteile der eigenen Software zu reduzieren?
- Dauer der Synchronisation reduzieren. Ein Lock sollte immer nur für eine möglichste kurze Zeitspanne gehalten werden, d.h. länger dauernde Operationen (z.B. I/O) gehören generell nicht in einen synchronized-Block, sondern sollten ausgelagert werden. Analog kann man überlegen, ob man eine Methode als Ganzes synchronized deklararieren muss oder ob man nicht besser einen kleineren synchronized-Block verwenden könnte, der wirklich nur die zu schützenden Anweisungen enthält und nichts Überflüssiges.
- volatile- und atomic Variablen benutzen. Man kann Synchronisation durch Verwendung von atomaren Variablen vermeiden und beispielsweise als Zähler einen AtomicInteger anstelle eines gewöhnlichen int verwenden, weil der AtomicInteger atomare increment- und decrement-Methoden hat und ohne Synchronisation auskommt. Man kann Sichtbarkeit von Datenmodifikationen auch durch volatile anstelle von Synchronisation erzielen, wenn lediglich einfache Zugriffe auf primitive Daten nötig sind (siehe / JMM1 /).
- Lock-Splitting / Lock-Striping verwenden. Statt alle Zugriffe auf gemeinsam verwendete veränderliche Daten mit nur einem einzigen Lock zu schützen, kann man überlegen, ob sich separate Teile der Daten mit separaten Locks schützen lassen. Damit wird die Wahrscheinlichkeit von Kollisionen reduziert, die Threads warten insgesamt seltener und tendenziell steigt die Parallelität.
- Unveränderliche Daten verwenden. Die Notwendigkeit für Sequentialisierung mit Hilfe von Locks besteht nur für gemeinsam verwendete Daten, die veränderlich sind. Wenn die gemeinsam verwendeten Daten sich nicht ändern können, dann wird keine Synchronisation benötigt. Das heißt, wo immer es möglich ist, sollten Immutable Types verwendet werden. Wenn keine adequaten Immutable Types vordefiniert sind, dann wird man bei Bedarf solche Typen selber implementieren müssen. Dabei spielen die JMM-Garantien für final-Variablen eine Rolle (siehe / JMM2 /).
- Gemeinsamverwendung vermeiden. Statt Daten mit anderen Threads gemeinsam zu verwenden, kann man überlegen, ob es nicht sinnvoll wäre, eine thread-lokale Kopie zu ziehen und diese zu verwenden. Dann wird für diese Daten keine Synchroniation mehr gebraucht, weil sie nicht mehr gemeinsam verwendet werden. Die CopyOnWriteArrayList im JDK verwendet eine solche Technik.
- Lock-Free Programming. Man kann versuchen, Algorithmen zu verwenden oder zu entwickeln, die so geschickt auf gemeinsam verwendete veränderliche Daten zugreifen, dass kein Lock gebraucht wird, weil ausschließlich atomare Operationen ausgeführt werden. Solche Algorithmen zu entwickeln ist heute aber noch eher ein Forschungsthema als eine in der Praxis häufig eingesetzte Technik. Oft lassen sich die Datenzugriffe auch gar nicht so gestalten, dass lock-free programmiert werden kann. Es gibt im JDK Beispiele von Datenstrukturen, nämlich die Concurrent Collections im Package java.util.concurrent, die mit solchen Algorithmen implementiert sind. Man sollte also versuchen, Concurrent Collections anstelle von Synchronized Collections oder selbstgeschriebenen Collections zu verwenden.
Zusammenfassung
In diesem Beitrag haben wir gesehen, dass Synchronisation teuer ist und worin die Kosten bestehen. In Multi-Prozessor- oder Multicore-Umgebungen wirkt sich die Synchronisation negativ auf die Skalierbarkeit des Programms aus. Tendenziell wird man also versuchen, Synchronisation zu reduzieren oder nach Möglichkeit ganz zu vermeiden. Techniken dafür haben wir kurz angesprochen. Dabei spielen volatile-, final- und atomare Variablen eine Rolle. Deshalb werden wir uns in den nächsten Beiträgen diese Variablen genauer ansehen.Literaturverweise und weitere Informationsquellen
| /AMDL/ |
"Validity of the Single Processor Approach to Achieving
Large-Scale Computing Capabilities"
Gene Amdahl AFIPS Conference Proceedings, (30), pp. 483-485, 1967 |
Die gesamte Serie über das Java Memory Model:
| /JMM1/ |
Einführung in das Java Memory Model: Wozu
braucht man volatile?
Klaus Kreft & Angelika Langer, Java Magazin, Juli 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/37.JMM-Introduction/37.JMM-Introduction.html |
| /JMM2/ |
Überblick über das Java Memory Model
Klaus Kreft & Angelika Langer, Java Magazin, August 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/38.JMM-Overview/38.JMM-Overview.html |
| /JMM3/ |
Die Kosten der Synchronisation
Klaus Kreft & Angelika Langer, Java Magazin, September 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/39.JMM-CostOfSynchronization/39.JMM-CostOfSynchronization.html |
| /JMM4/ |
Details zu volatile-Variablen
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/40.JMM-volatileDetails/40.JMM-volatileDetails.html |
| /JMM5/ |
volatile und das Double-Check-Idiom
Klaus Kreft & Angelika Langer, Java Magazin, November 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/41.JMM-DoubleCheck/41.JMM-DoubleCheck.html |
| /JMM6/ |
Regeln für die Verwendung von volatile
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/42.JMM-volatileIdioms/42.JMM-volatileIdioms.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||