| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Memory Model:
Überblick
Das Java-Memory-Modell im Überblick
Java Magazin, August 2008
|
Dies ist das
Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective
Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser
Serie sind ebenfalls verfügbar (
click
here
).
|
Im letzten Beitrag unserer Reihe über Aspekte des Java-Memory-Modells (JMM) haben wir erläutert, dass man das volatile-Schüsselwort zum Zwecke der Optimierung verwendet, um die relative teure Synchronisation von konkurrierenden Zugriffen auf gemeinsam verwendete veränderliche Daten zu vermeiden. Dabei haben wir die Sichtbarkeitsregeln erwähnt, die sich im Zusammenhang mit volatile und Synchronisation aus dem Java-Memory-Modell ergeben (siehe / JMM1 /). In diesem Beitrag wollen wir einen Überblick über das Memory-Modell geben.
Im Zusammenhang mit volatile und Synchronisation haben wir den Begriff der Sequential Consistency erwähnt. Das ist ein Modell, mit dem sich viele Java-Entwickler das Multithreading in Java vorstellen, obwohl Java gar keine Sequential Consistency unterstützt. Wenn man dennoch so programmiert, als gäbe es Sequential Consistency in Java, dann können Fehler entstehen wie jener, den wir im letzten Beitrag besprochen haben.
Das Modell der Sequential Consistency ist ein relativ einfaches Datenkonsistenzmodell. Es ähnelt der Funktionsweise von Multithreading auf einer Single-CPU-Umgebung. Die Vorstellung ist: die Threads laufen nicht wirklich parallel, sondern es gibt einen Thread-Scheduler, der den einzelnen Threads abwechselnd Zeitscheiben der CPU zuteilt. Ein Thread darf ein paar Operationen ausführen, wird dann verdrängt, es kommt ein anderer Threads dran, der wiederum ein paar Operationen machen darf, usw., so dass die einzelnen Threads ihre Operationen in einer sequenziellen Reihenfolge ausführen. Damit verbunden ist die Vorstellung, dass Threads, die später drankommen, Modifikationen im Speicher sehen können, die von Threads vorgenommen wurden, die vorher dran waren. Das ist ein einfaches Konsistenzmodell, das aber in Java nicht unterstützt wird.
Bei einem Konsistenzmodell geht es ganz allgemein (unabhängig von Java) um Regeln für die Zugriffe auf den Speicher. Wenn sich der Programmierer an die Regeln hält, dann gibt ihm das System (in unserem Falle Java und seine virtuelle Maschine) Garantien für die Effekte von Speicherzugriffen, damit der Programmierer weiss, was zur Laufzeit geschehen wird, und er die Effekte seiner Speicheroperationen vorhersehen kann. In High-Level-Sprachen wie Java müssen der Compiler und das Laufzeitsystem dafür sorgen, dass die High-Level-Sprachkonstrukte gemäß den Regeln des Konsistenzmodells in Low-Level-Operationen umgesetzt werden.
Auch Java hat ein Konsistenzmodell. Es ist aber nicht das Modell der Sequential Consistency, sondern Java hat ein eigenes Memory-Modell, das als JMM (= Java Memory Model) bezeichnet wird. Seine Regeln sind deutlich anders und schwächer als die der Sequential Consistency.
Wir wollen in diesem Beitrag einen Überblick über die Regeln des JMM geben. Das Thema ist ein wenig theoretisch und es ist nicht unmittelbar einsichtig, was all die Regeln für die Praxis der Java-Programmierung bedeuten. Trotzdem wollen wir erst einmal einen Überblick über das Modell als solches geben, ehe wir in nachfolgenden Beiträgen dieser Reihe die einzelnen Aspeke noch einmal näher auf ihre Bedeutung für die Praxis untersuchen.
Das Java-Memory-Modell
|
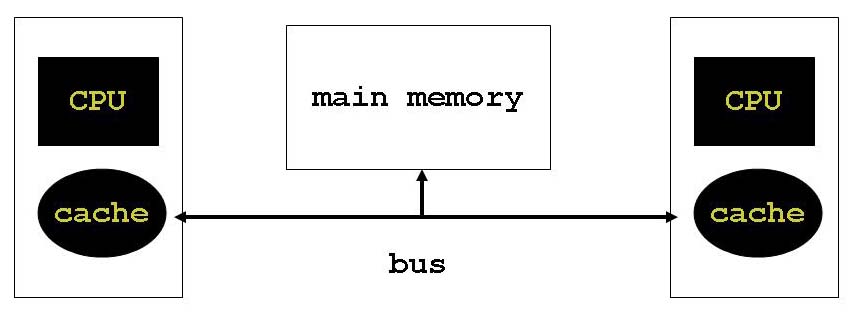
Das Memory-Modell in Java ähnelt einer abstrakten SMP (= symmetric multi processing)-Maschine: die Threads laufen parallel und konzeptionell haben alle Threads Zugriff auf einen gemeinsamen Hauptspeicher (main memory), in dem die gemeinsam verwendeten Variablen abgelegt sind. Daneben hat jeder Thread einen eigenen lokalen Speicherbereich (cache), in den er Variablen hineinladen und lokal bearbeiten kann. Das Zurückschreiben der lokalen Daten in den Hauptspeicher (flush) und das Hereinladen von Daten aus dem Hauptspeicher (refresh) muss nach den Regeln des JMM geschehen. Das JMM beschreibt nun, in welcher Reihenfolge Aktionen passieren und welche Aktionen einen Flush oder Refresh auslösen. |
Eine dieser Regeln besagt zum Beispiel, dass beim Start eines Threads
alle relevanten Daten aus dem Hauptspeicher in den lokalen Arbeitsspeicher
des Threads geladen werden. Dann darf der Thread mit diesen lokalen
Daten arbeiten und muss gar nicht mehr ins Main Memory schauen, weil er
die Daten im Cache hat. Am Ende des Threads muss der gesamte lokale
Arbeitsspeicher des Threads wieder in den Hauptspeicher zurückgeschrieben
werden. Daraus ergibt sich das Verhalten, dass wir auch intuitiv
erwarten. Wenn ein Thread mit join auf das Ende eines anderen Threads
wartet, kann der wartende Thread sehen, welche Modifikationen der andere,
bereits beendete Thread gemacht hat.
| Das JMM ist auch wieder nur ein Modell, mit dem sich der Java-Programmierer das Verhalten von Threads in einer JVM erklären kann. In Wirklichkeit muss die virtuelle Maschine die Regeln des JMM auf die Hardware abbilden, die ihr eigenes Hardware-Memory-Modell hat. Die heutigen Multicore-Prozessoren arbeiten nicht nur mit einem Cache pro Prozessorkern, sondern teilweise mit mehreren Ebenen von Caches und komplexeren Caching-Mechanismen, als sie das JMM vorsieht. Deshalb fällt der virtuellen Maschine die Aufgabe zu, mit geeigneten Anweisungen an die Hardware die Regeln des JMM zu implementieren. |

|
Sichtbarkeitsregeln im JMM
Das Memory-Modell von Java regelt drei Dinge:
- Atomicity. Welche Operationen sind atomar, d.h. werden nicht durch andere Threads unterbrochen?
- Ordering. In welcher Reihenfolge passieren die Aktionen?
- Visibility. Wann werden Modifikationen im Speicher anderen Threads sichtbar gemacht?
Bei der Atomicity geht es zum Beispiel darum, dass der Zugriff auf Variablen von primitivem Typ (außer long und double) sowie auf Referenzvariablen ununterbrechbar ist. Gleiches gilt für volatile-Variablen (diesmal inklusive long und double). Die Operationen auf atomaren Variablen im Package java.util.concurrent.atomic sind ununterbrechbar. Gleiches gilt für einige der Operationen der Concurrent Collections im Package java.util.concurrent, z.B. die Methode putIfAbsent der ConcurrentMap. Bei Referenzvariablen darf man nicht vergessen, dass stets nur der Zugriff auf die Referenz selbst, d.h. auf die Adresse, atomar ist, nicht etwa der Zugriff auf das referenzierte Objekt. Ansonsten sind die Regeln zur Atomarität relativ einfach zu verstehen.
Beim Ordering geht es darum, unter welchen Umständen ein Thread die Effekte von Operationen, die ein anderer Thread ausführt, in der Reihenfolge sehen kann, in der der andere Thread die Operationen vorgenommen hat. Im allgemeinen ist nämlich ein weitrechendes Re-Ordering erlaubt, an dem sich der Compiler, die virtuelle Maschine und die Hardware beteiligen. Das Re-Ordering führt dazu, dass zwar innerhalb eines Threads klar ist, in welcher Reihenfolge die Effekte der Operationen entstehen, aber ein anderer Thread, der sich das anschaut, sieht die Effekte u.U. in einer anderen Reihenfolge, als sie produziert wurden. Es gibt im JMM Regeln für das Ordering, aber sie sind komplex und damit schwer zu verstehen. Deshalb sehen wir uns das Ordering nicht jetzt, sondern in einem späterem Beitrag genauer an.
Bei der Visibility geht es darum, ob und wann Modifikation am Speicher,
die ein Thread gemacht hat, den anderen Threads sichtbar werden.
Die Sichtbarkeitsregeln des JMM geben eine Reihe von Garantien, von denen
wir einige auch schon im letzten Artikel erwähnt haben:
- Threadstart- und -ende . Der Start eines Threads löst einen Refresh des threadlokalen Arbeitsspeichers aus dem Hauptspeicher aus, das Ende des Thread einen Flush. Das entspricht der Intuition. Wenn zum Beispiel ein Thread mit join auf das Ende eines anderen Threads wartet, kann der wartende Thread sehen, welche Modifikationen der andere, bereits beendete Thread an gemeinsam verwendeten Daten gemacht hat.
- Synchronisation . Der Erhalt eines Locks löst einen Refresh aus, das Freigeben des Locks löst einen Flush aus. Das gilt für die alten impliziten, aber auch für die neuen expliziten Locks. Auch dieses Verhalten entspricht unserer Intuition. Alle Threads, die dasselbe Lock verwenden, durchlaufen die Sequenz der mit diesem Lock synchronisierten Anweisungen nicht parallel sondern nacheinander. Das heißt, es ist klar, dass zunächst ein Thread auf gemeinsam verwendete Daten zugreift und erst danach ein anderer. Da beim Freigeben des Locks der eine Thread alle lokalen Daten in den Hauptspeicher zurück schreiben muss und der nächste Thread beim Erhalt des Locks seinen lokalen Arbeitsspeicher aus dem Hauptspeicher auffrischen muss, sieht der zweite Thread alle Modifikationen, die der erste Thread an den gemeinsam verwendeten Daten vorgenommen hat.
- Lese- und Schreibzugriff auf volatile-Variablen. Das Lesen einer volatile-Variablen löst einen Refresh aus, das Modifizieren einer volatile-Variablen löst einen Flush aus. Das bedeutet, dass ein Thread, der den Inhalt einer volatile-Variablen liest, den Wert nicht aus seinem Arbeitsspeicher holen darf, sondern ihn aus dem Main Memory holen muss. Dabei muss er nicht nur den Inhalt der betreffenden volatile-Variablen holen, sondern er muss seinen gesamten Arbeitsspeicher auffrischen. Auf diese Weise sieht er alle Modifikation an gemeinsam verwendeten Variablen, die zuvor ein anderer Thread gemacht hat, der auf dieselbe volatile-Variablen vorher schreibend zugegriffen hat. Denn beim schreibenden Zugriff muss der andere Thread seinen gesamten Arbeitspeicher in den Hauptspeicher zurückgeschrieben haben. Was das genau in der Praxis bedeutet, sehen wir uns in einem späteren Beitrag noch einmal genauer an.
- Lese- und Schreibzugriff auf atomare Variablen. Mit den atomaren Variablen sind die Abstraktionen aus dem Package java.util.concurrent.atomic gemeint. Das Lesen einer atomaren Variablen per get-Methode löst einen Refresh aus, das Modifizieren per set-Methode löst einen Flush aus. Darüber hinaus gibt es Methoden, die beides bewirken, z.B. compareAndSet und getAndIncrement. Mit anderen Worten, atomare Variablen haben Speichereffekte wie die volatile-Variablen und haben darüber hinaus atomare read-and-modify-Operationen, die die volatile-Variablen nicht haben. Auch dazu später mehr.
- Erstmaliger Lesezugriff auf final-Variablen. final-Variablen werden bekanntlich spätestens im Konstruktor mit ihrem konstanten Wert initialiert. Das Ende der Konstruktion löst einen partiellen Flush aus, bei dem die final-Variablen und alle "abhängigen" Objekte in den Hauptspeicher zurückgeschrieben werden. Die "abhängigen" Objekte sind jene, die von einer final-Variablen aus per Referenz erreichbar sind. Der erste lesende Zugriff auf eine final-Variable löst einen partiellen Refresh aus, bei dem die final-Variable und alle "abhängigen" Objekte in den Arbeitsspeicher geladen werden. Ein erneuter Refresh erfolgt nicht, weil die Variable einen konstanten Inhalt hat, der sich nicht mehr ändert. Auch das wollen wir uns in einem späteren Beitrag im Detail ansehen.
Zusammenfassung
Wir haben uns angesehen, was das Java-Memory-Modell überhaupt ist; es geht dabei um Regeln für Speicherzugriffe. Wir haben daran erinnert, dass wir keine Sequential Consistency in Java haben, sondern stattdessen das Java-Memory-Modell (JMM) mit seiner SMP-artigen Vorstellung von Hauptspeicher und threadlokalen Arbeitsspeichern. Das JMM regelt Ununterbrechbarkeit von Operationen, Sichtbarkeit von Speichereffekten und die Reihenfolge von Operationen. Wir werden uns bei nächsten Mal überlegen, warum es überhaupt wichtig ist, das JMM und seine Regeln zu kennen - ehe wir uns in nachfolgenden Beiträgen in die Details vertiefen.Literaturverweise und weitere Informationsquellen
| /JLS/ |
Java Language Specification, 3rd Edition
Chapter 17: Threads and Locks URL: http://java.sun.com/docs/books/jls/third_edition/html/memory.html |
Die gesamte Serie über das Java Memory Model:
| /JMM1/ |
Einführung in das Java Memory Model: Wozu
braucht man volatile?
Klaus Kreft & Angelika Langer, Java Magazin, Juli 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/37.JMM-Introduction/37.JMM-Introduction.html |
| /JMM2/ |
Überblick über das Java Memory Model
Klaus Kreft & Angelika Langer, Java Magazin, August 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/38.JMM-Overview/38.JMM-Overview.html |
| /JMM3/ |
Die Kosten der Synchronisation
Klaus Kreft & Angelika Langer, Java Magazin, September 2008 URL: http://www.AngelikaLanger.com/Articles/39.JMM-CostOfSynchronization/39.JMM-CostOfSynchronization.html |
| /JMM4/ |
Details zu volatile-Variablen
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/40.JMM-volatileDetails/40.JMM-volatileDetails.html |
| /JMM5/ |
volatile und das Double-Check-Idiom
Klaus Kreft & Angelika Langer, Java Magazin, November 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/41.JMM-DoubleCheck/41.JMM-DoubleCheck.html |
| /JMM6/ |
Regeln für die Verwendung von volatile
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2008 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/42.JMM-volatileIdioms/42.JMM-volatileIdioms.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||