| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
Insert Iterators
C++ Report, February 1999
Klaus Kreft & Angelika Langer
![]()
In a series of articles published in our column "Effective Standard
Library" in C++ Report in 1999 we discussed special groups of iterators:
insert iterators, stream iterators, and stream buffer iterators. They need
special attention because they differ from other iterators in that they
do not fully behave like pointer-like objects, i.e. they break the analogy
to pointers to some extent. The notion of an STL iterator is often explained
and understood as a pointer-like object, i.e. something like a built-in
pointer referring to a built-in array. While this is a valid analogy in
many situations, it is kind of misleading, or at least confusing, when
applied to insert and stream iterators. In this an the next installments
we will see why. Let us start with a brief recap of iterators and then
discuss insert iterators. Stream iterators will be covered in the next
article.
Iterator Recap
With the adoption of Hewlett-Packard’s STL as part of the Standard Library, the concept of generic programming was introduced into the Standard Library. The essential idea of generic programming is to separate a data structure (container) from the operations (algorithms) performed on the data structure. Iterators are provided by the container and used to connect the algorithm with the container. Iterators are pointer-like objects that provide an interface that allows the algorithm to traverse the container and to access and mutate the container’s elements. The following code shows an example. The find -algorithm is applied to a list of integers to see whether one of the list’s elements is 0 :void foo(list<int>& myList)The member function begin() yields an iterator that refers to the first element of the list, while end() yields an iterator one past the end of the list. The find -algorithm traverses this iterator range inspecting if any of the elements of the list matches the value specified by the last parameter (see implementation of find below). If it has reached the iterator specified by the second parameter without finding any match it returns this iterator, which refers past the end of the list. Otherwise, when find has found a matching element in the list, it returns an iterator referring this element.
{
if (find(myList.begin(), myList.end(), 0) != myList.end())
cout << "Found a 0 in the list." << endl;
}
template <class Iterator, class T>There are two aspects in find which are typical for standard library algorithms and their relation to iterators:
Iterator find ( Iterator first, Iterator end, const T& value)
{
while (first != end && *first != value) // line 1
first++; // line 2
return first; // line 3
}
- the way iterator ranges are used and
- the way algorithms are implemented generically based on the iterators’ types.
Iterator Ranges and Past-The-End Iterators.
An iterator range is specified by two iterators. The first one indicates the beginning of the range and the second one the end. All iterator positions in that range can be reached by consecutively applying ++ (either postfix or prefix) to the first iterator until ++ yields the end iterator. The end iterator is excluded from the iterator range (denoted as: [ first,last ) ). It need not even refer to a valid container element; it only has to be reachable. This past-the-end iterator can be used to indicate failure: When an algorithm normally returns a valid iterator from the iterator range as the result of its task, then it can return the past-the-end iterator to indicate that it failed to accomplish the task. The find -algorithm shown above does so when it cannot find the specified value. Hence, iterator ranges specify sequences of elements that an algorithm can step through, and the end iterator can also be used by an algorithm as an error indication.Iterator Categories.
Algorithms are generic with respect to the types of the iterators they use. An algorithm is usually implemented as a function template that has one or more iterator types as template parameters.The interface required of these iterator types is determined by the operations that an algorithm applies to the iterators. These operations can be the public member functions when the iterator is a class. When the iterator is a built-in type the operations used are the built-in operations for that type. In the example above, the find -algorithm has only one iterator type template parameter. The operations used from this iterator type’s interface are the != operator and the * operator in line 1, the postfix ++ operator in line 2, and the copy constructor in line 3. That's all the find -algorithm requires of an iterator type.
The interface supported by an iterator type depends on the kind of the container that provides it. Take for example the standard library’s list , which is a doubly-linked list. It can be iterated in forward and backward direction. Hence, it provides an iterator to whom the pre- and postfix operator++ and operator-- can be applied. A vector , on the other hand, need not to be iterated element by element, but allows steps of arbitrary size. It provides an iterator to whom the operator+(Distance) and operator-(Distance) can be applied. In other words, the characteristics of a container determine the interface of the iterators it provides.
While the interface of an iterator depends on the container, it is the algorithm that can optimize its implementation according to the iterator’s interface. A typical example is the advance -algorithm, which increments or decrements an iterator. It can be implemented for a vector in the following way:
i += n;while it must be implemented for a list in a more runtime consuming way:
if (n >= 0)The standard library classifies the iterator types according to their interfaces into five categories:
while (n--)
i++;
else
while (n++)
i--;
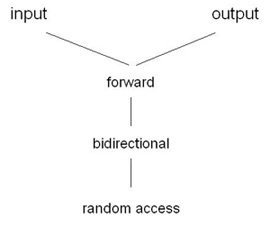
Note that this figure does not show inheritance relationships. Iterator categories are just abstractions which represent a set of requirements to an iterator’s interface. As already mentioned above individual iterators are free to satisfy these requirements by different means, i.e. built-in operators, member functions, global functions, etc. For detailed explanations of the requirements consult your library manual or take a look at one of the publications given as reference /2/-/4/ . In brevity:
- Input iterators allow algorithms to advance the iterator and give "read only" access to the value.
- Output iterators allow algorithms to advance the iterator and give "write only" access to the value.
- Forward iterators combine read and write access, but only in one direction (i.e., forward).
- Bidirectional iterators allow algorithms to traverse the sequence in both directions, forward and backward.
- Random access iterators allow jumps and "pointer arithmetics".
Iterator Adapters.
Another issue related to standard library iterators is the idea of iterator adapters . An iterator adapter takes an iterator and transforms it into another iterator that has a different behavior. A typical example from the standard library is the reverse_iterator . It reverts the direction in which the iterator traverses a collection. Or simpler: the operator++() of the reverse iterator adapter calls the operator--() of the original iterator. As you might already guess from this description, it is a precondition that the original iterator is at least a bidirectional iterator.Insert Iterators
To motivate the need for insert iterators, lets start with an example. Assume we have two iterator ranges, defined by [ sourceBegin,sourceEnd ) and [ targetBegin,targetEnd ). Then the following code:while (targetBegin != targetEnd && sourceBegin != sourceEnd)copies the elements from the source iterator range into the target iterator range, overwriting the elements that initially existed in the target range. The copying stops when either the source or the target range is exceeded.
*targetBegin ++ = *sourceBegin ++;
The above is a typical pointer idiom and thanks to the generic structure of the standard library this works fine, not only for pointers but also for iterators referring to elements of a container. The only precondition is that container.begin() <= targetBegin <= targetEnd <= container.end() .
As mentioned before, the elements of the container between targetBegin and targetEnd will be overwritten. An interesting question is if it is possible to use the same code to insert the new elements into the container instead of overwriting the existing elements. We might consider inserting them right before the position denoted by the iterator targetBegin . In that case, we would see the iterator as a cursor pointing into the container, which we would want to switch from the regular overwrite mode to insert mode.
The standard library has the notion of iterator adapters. In the recap, we mentioned the example of the reverse_iterator , which switches an existing iterator from forward mode to backward mode. Similarly, the standard library contains an adapter that offers what we are looking for: the insert_iterator . It switches an existing iterator from overwrite mode to insert mode.
Let us see how an insert_iterator can be used to rewrite the code snippet above, in order to achieve insertion instead of overwriting. What would we have to change? Well, instead of a range that we want to overwrite, we have a position before which we intend to insert elements. The rewritten code snippet looks like this:
insert_iterator<Container> insertIter(container, target);Instead of the target range [ targetBegin,targetEnd ) we have:
while (sourceBegin != sourceEnd)
*insertIter ++ = *sourceBegin ++;
- a container of type Container into which the new elements are inserted and
- a target iterator referring to a position inside this container; the iterator denotes the position before which the new elements are inserted.
How do insert iterators work?
We started this article with the remark that often people see iterators as something like a built-in pointer referring to a built-in array. Indeed, a built-in pointer referring to a built-in array can be seen as an iterator. Note, however, that this iterator cannot be switched to insert mode, because insertion would make the array grow, but built-in arrays are of fixed size. Here, the analogy between iterators and pointers breaks. All standard library containers are of dynamic size, whereas a built-in array is a fixed-size container. For this reason, an iterator can be switched into insert mode and a pointer cannot.
This is also visible in the implementation of the insert_iterator . It uses the container’s member function insert , which is defined as:
iterator insert(iterator position, const T& newElement);The type iterator is the container’s iterator type; it is provided by a nested typedef inside the container' s public section. The type T is the container’s element type; it is a template parameter of the container's class template. The functionality of insert is very straightforward: It inserts a copy of newElement before position and returns an iterator referring to the inserted copy.
Which iterator category do insert iterators belong to?
To classify the insert_iterator into an iterator category we have to ask ourselves: Which functionality, in terms of member functions, do we expect from the insert_iterator ? In our example above we have used the operator++ . Additionally we have used the operator* on the right hand side of an assignment, which means we require write access to the value the iterator refers to. Comparing this functionality with the brief description we gave of the iterator categories earlier, we find that the insert_iterator should be an output iterator. The standard, not surprisingly, specifies the insert_iterator ’s synopsis as follows:
template <class Container>
class insert_iterator :
public iterator<output_iterator_tag,void,void,void,void>
{
public:
typedef Container
container_type;
insert_iterator<Container>(Container&
c, typename Container::iterator i);
insert_iterator<Container>&
operator= (typename Container::const_reference value);
insert_iterator<Container>&
operator*();
insert_iterator<Container>&
operator++();
insert_iterator<Container>&
operator++(int);
protected:
Container*
container;
typename
Container::iterator iter;
};
Do not worry too much about the base class iterator<output_iterator_tag, void, void, void, void> . It just means that the insert_iterator identifies itself as an output iterator. We will discuss the "voids" in our subsequent article.
How are operations of an insert iterator implemented?
Let's take a more thorough look at the implementation of insert_iterator ‘s member functions. The constructor is easy. It receives a container and an iterator which it saves in its protected data members:
insert_iterator<Container>The other member functions are supposed to work together in order to support the pointer idioms shown in the previous example:
(Container& c, typename Container::iterator i) : container(&c), iter(i) {}
insertIter.operator*().operator++(int).operator=(*sourceBegin ++);Which of these operations shall do the actual insertion?
For two reasons operator= is the one to call insert . First, it is the only one of the three operators whose signature allows to receive an argument. We can pass the value that shall be inserted in the container as an argument to the insert_iterator ’s assignment operator. Secondly, the semantics of "assigning a value to a container iterator" can be interpreted as "inserting the value into the container". It would feel kind of awkward if dereferencing or incrementing an iterator would mean "inserting the value into the container".
Okay, we're ready to try a tentative first implementation of operator=(typename Container::const_reference value) . The function body would be something like this:
container->insert(iter, value);Not bad for a first try. However, there's a snag here. What happens if the container must be resized due to insertion of an additional element? Think of a vector : It's capacity might be exhausted (see figure 2a). Hence, insertion of an element requires: New memory for the elements must be allocated, elements must be copied, and the old memory must be released. After that iter has become invalid, because it still refers to some old, meanwhile released, memory location(see figure 2b).
return *this;
Here it comes in handy that the container's member function insert returns an iterator to the newly inserted value. If we advance this returned iterator one step (by applying ++) then it refers to the position in the container before which the next value should be inserted, and we can make this position our new iter value:
insert_iterator<Container>& operator=(typename Container::const_reference value)
{
iter = container->insert (iter, value);
iter++;
return *this;
}
(See figure 2c).
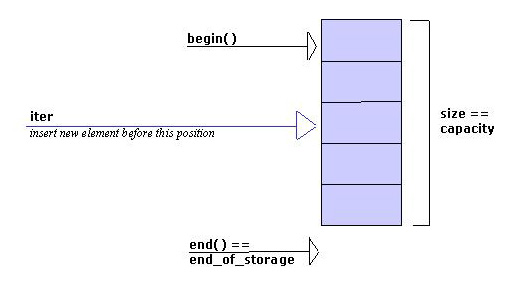 Figure
2a: Situation
before
insertion into a full vector
Figure
2a: Situation
before
insertion into a full vector
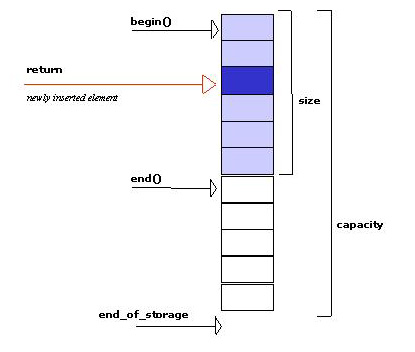
Figure 2b: Situation
after
insertion into a
full vector
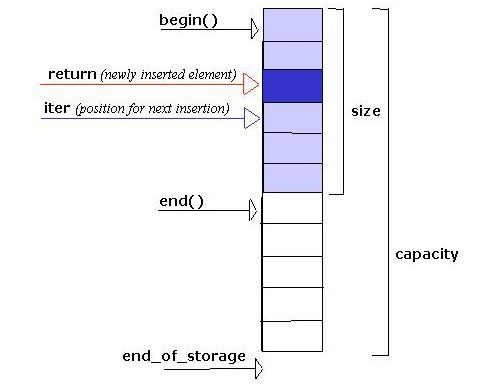
Figure 2c: Situation after adjustment of iter
Now that we have implemented operator= , we can take a look at the implementation of the other operators. It almost looks like there were no functionality left over for them. Instead of having them do nothing we make them return a reference to self:
insert_iterator<Container>& operator*() { return *this; }This allows to chain operator* , and operator++ before operator= and the operator chain
insert_iterator<Container>& operator++() { return *this; }
insert_iterator<Container>& operator++(int) { return *this; }
insertIter.operator*().operator++(int).operator=(*sourceBegin ++);works as expected. A good compiler can optimize this line of code by eliminating the code of operator* and operator++ and would compress it to something like:
insertIter.operator=(*sourceBegin ++);
Afterthought: What are iterators?
We explained the implementation of the insert_iterator because we feel it helps to broaden the understanding of what an iterator in the standard library can be. In essence, an iterator is an abstraction that provides the operations required for the iterator category that it belongs to. In general, these operations are always a subset of the operations that a built-in pointer provides. There are, however, no carved-in-stone rules for the syntax or semantics of an individual iterator operation. For example, it is not guaranteed that an operation of an iterator implements a functionality that corresponds to the semantics of the same operation for a built-in pointer. It is allowed and sometimes sensible to break the analogy between an iterator and a built-in pointer.
Recall the insert_iterator ’s operator++ . It is implemented by a single line of code: return *this; . This code does not do anything of what is typically associated with an increment operation for a built-in pointer. We would expect something like: advance the pointer one step so that it refers the next data element. Also, look at the return type of the insert_iterator ’s operator* . It returns a reference to an insert iterator. Wouldn't one expect a reference to the value the iterator points to? The bottom line is that the individual operations of an insert iterator have surprising and counter-intuitive semantics. Only in combination they mimic pointer-like semantics, like we've seen it in:
*insertIter ++ = *sourceBegin ++;The flip side of this free interpretation of the semantics of an iterator's operations is that it allows to write correct code that looks wrong and hence is hard to comprehend. Here is an example: We could write the following code to insert the elements from the source iterator range [ sourceBegin, sourceEnd ) into the container before the position denoted by target :
insert_iterator<Container> insertIter(container, target);We strongly discourage writing code like this. It's correct and it works, yet it obfuscates the intent. Everybody who understands iterators as pointer-like objects might have a hard time to see what's going on in this while loop.
while (sourceBegin != sourceEnd)
insertIter = *sourceBegin ++;
Additional Remarks on Insert Iterators
With the last remarks the column has already come full cycle: we have seen that the analogy between iterators and pointers only partially hold for insert iterators and how freely iterator operations can be interpreted. There are two additional issues we want to cover because they are so closely related to the insert_iterator . The first is a subtle problem in the iterator’s usage and the second are two other iterator adaptors: front_insert_iterator , back_insert_iterator which together with the insert_iterator form the family of insert iterators.Temporary insert iterators
Throughout all code samples in this article, we explicitly defined a named instance of the insert_iterator whenever we used one. We did so because creating only a temporary insert_iterator introduces a subtle problem. Consider:
while (sourceBegin != sourceEnd)A temporary insert_iterator is constructed for each iteration of the loop. For each of the temporary insert_iterator s the insertion position is always specified by the iterator target . However, the memory location referenced by target might have become invalid after an iteration due to a necessary re-sizing of the container. This is a problem similar to the one we had encountered with the first try for the implementation of insert_iterator 's operator=.
*(insert_iterator(container,target)) ++ = *sourceBegin ++;
To avoid this problem it is recommended to use a non-temporary insert_iterator .
When the insertion position is specified by container.begin() or container.end() the situation is different. The member functions begin() and end() dynamically determine the respective positions. Prior to the construction of each temporary insert_iterator the iterator to be adapted is determined anew.
Note also the difference between using:
while (sourceBegin != sourceEnd)and:
*(insert_iterator(container,container.begin()))++ = *sourceBegin++;
insert_iterator<Container> insertIter(container, container.begin());The first code snippet makes each newly inserted element the first element of the container, while the latter inserts all element before the position that used to be container.begin() when the loop was started. Say, we have an empty list<int> and the source iterator range is [ &a[0],&a[4] ) where a[] is an integer array int a[4] = {1,2,3,4} . The first code snippet will result in a list which contains: 4,3,2,1, while the second leads to a list containing: 1,2,3,4.
while (sourceBegin != sourceEnd)
*insertIter ++ = *sourceBegin ++;
Front Inserter and Back Inserter
There are more elegant ways of inserting elements at the beginning or end of a container. The standard library provides two additional insert iterator adapters for this purpose: front_insert_iterator and back_insert_iterator .
The funny thing about them is that they are called iterator adapters although their constructors do not even receive an iterator that should be adapted. Their constructors’ only parameter is a container. The iterator to be adapted is implicitly specified: front_insert_iterator offers the same functionality as:
insert_iterator(container,container.begin())i.e. it inserts new elements always at the begin of the container. back_insert_iterator inserts new elements always at the end of the container, thus offering the same functionality as:
insert_iterator(container,container.end())We would call the functionality of both adapters "a kind of iterator adaptation", not really an iterator adaptation, because their actual implementation is not based on any iterators, not even container.begin() or container.end() . The front_insert_iterator , for instance, implements the assignment operator in the following way:
front_insert_iterator<Container>& operator=(typename Container::const_reference value)The back_insert_iterator calls container->push_back(value) in its corresponding assignment operator. push_front inserts a copy of value at the beginning of the container, while push_back does the same at the end.
{
container->push_front(value);
return *this;
}
While the
insert_iterator
adapter can
be applied to
all
types of containers in the standard library,
front_insert_iterator
and
back_insert_iterator
cannot. The reason
is that not all container types offer a
push_front
or
push_back
member function. Only those
containers for which these operations take constant time provide them.
The respective containers are for
push_front
:
list
,
deque
and for
push_back
:
vector
,
list
,
deque
.
Applying a
front_insert_iterator
or a
back_insert_iterator
to other containers will result in a compile error.
Summary
We have seen that the insert_iterator is an iterator adapter that provides an output iterator interface. While the container iterators only allow to overwrite existing container elements, the insert_iterator allows to insert new elements into a container. The semantic of an insert_iterator 's individual operations is completely different from what is normally assumed for a typical iterator that is often seen a pointer-like object. Only in combination the operations exhibit pointer-like semantics.References
/1/ Klaus Kreft & Angelika Langer
Combining OO Design and Generic Programming
C++ Report, March 1997
/2/ STL Tutorial and Reference Guide
David R. Musser and Atul Saini
Addison-Wesley, 1996
/3/ Generic Programming and the STL
Matthew Austern
Addison Wesley Longman, 1998
/4/ The C++ Programming Language, 3rd Edition
Bjarne Stroustrup
Addison Wesley Longman, 1997
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||